Why I wanted to build it
Quant Research Lab started from a frustration with normal quant demos: most of them show a clean equity curve, but hide the research process that produced it. The interesting question is usually not "can one strategy look good on one chart?" The harder question is whether the search process is honest after many trials, failed ideas, parameter mutations, cost assumptions, and overlapping factors.
I wanted the project to feel like a hacker terminal and an office simulation, but the purpose is serious: make the research loop visible. The user should be able to watch a hypothesis become code, watch the backtest fail or pass mechanical gates, and see the next hypothesis change because the system remembers what happened before. The anime office is the face. The real product is the traceable research process behind it.

This is also why I did not design it as a trading app. It displays historical simulations only. It has no brokerage connection, no order execution, and no claim that any candidate is safe to trade. The point is to study how autonomous research agents should behave when they are forced to leave evidence.
Tech stack
The public implementation is a browser-first research simulator built around a TypeScript stack:
- React 18 for the interactive office UI, panels, controls, and stateful visual system.
- TypeScript 5.6 for typed engines and safer state transitions.
- Vite 7 for fast local development and static builds.
- src/lib/office2d/officeDirector.ts for character movement, conversation orchestration, boss reactions, and office effects.
- src/engines/ for deterministic research logic: strategy knowledge, hypothesis generation, backtesting, risk review, and research memory.
- src/engines/dialogue/ for local data-grounded dialogue scripts and optional browser-side model condensation.
- Wallpaper packaging for Lively Wallpaper and Wallpaper Engine, so the same research loop can run as a desktop surface.
The stack choice is intentionally simple. A browser app is easy to inspect, easy to ship through GitHub, and good enough to demonstrate the research-loop architecture. The project does not need a server to prove the core idea because the most important behavior is deterministic: generate a candidate, backtest it, score it, review it, remember it, and propose the next move.
How I built the system
The architecture separates the office surface from the research engines. The office layer can be playful, but the engine layer has to be explicit. That split prevents the visual style from becoming the only thing the project does.

The research loop has five main steps.
- The hypothesis engine chooses a direction. It can explore a new family, refine a promising line, repair a failure, or steer toward a boss directive.
- The strategy knowledge base constrains the idea. The README describes 15 documented equity families, including momentum, PEAD, news sentiment, low-volatility, pairs, lead-lag, and seasonality.
- The backtest engine simulates the candidate and produces metrics that the rest of the system can inspect.
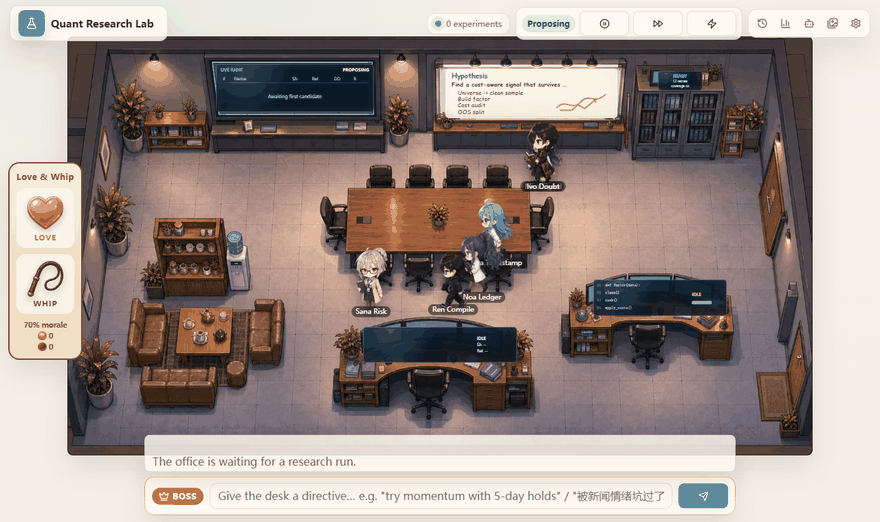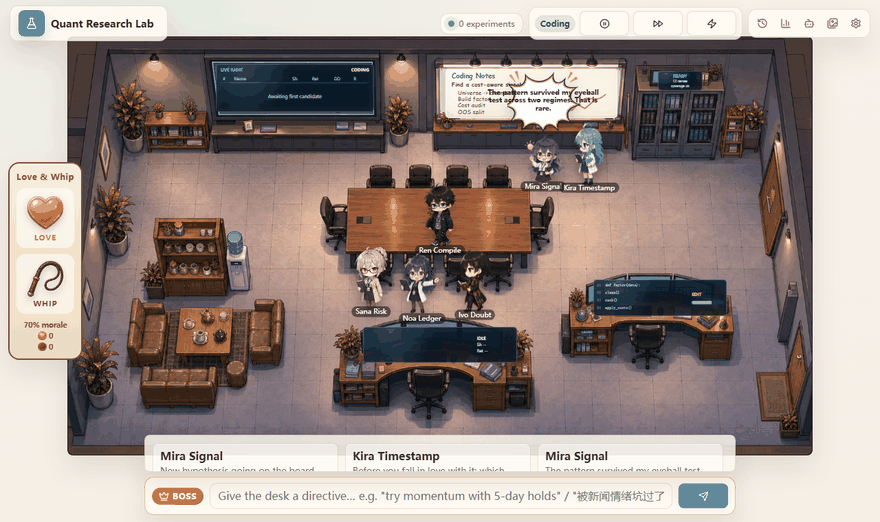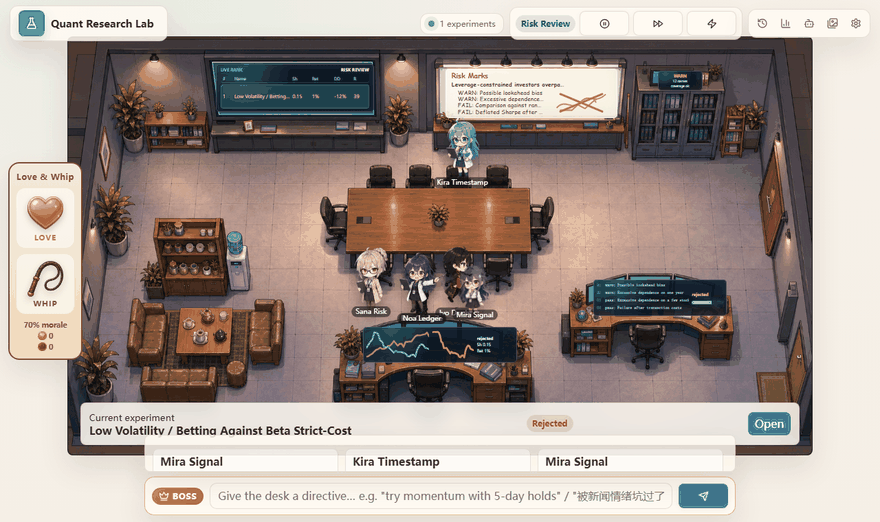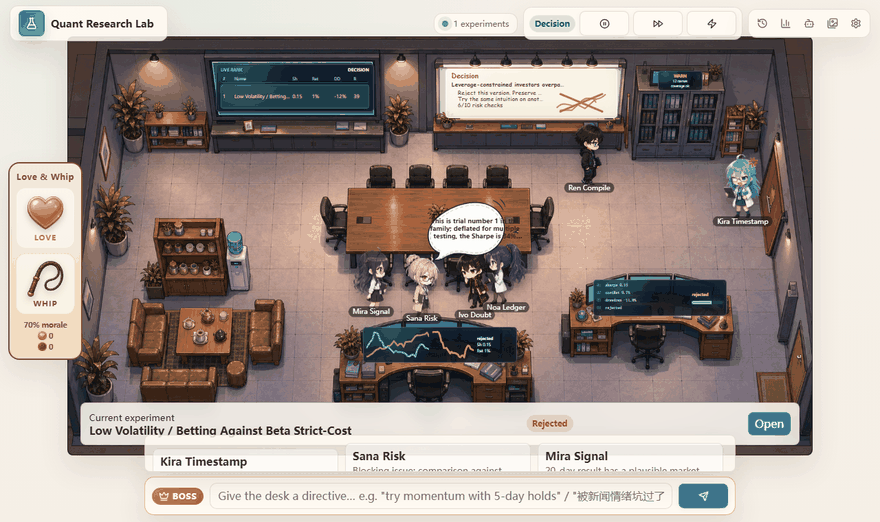
- The risk review engine applies mechanical gates. A candidate can be blocked by deflated Sharpe, cost, turnover, drawdown, baseline comparison, or alpha-pool correlation.
- The research memory stores the outcome. Promising strategies can become v2 or v3 descendants; repeated mining of the same family can decay its edge.

The boss interface sits above that loop. It lets the user type a directive, praise a researcher, criticize a researcher, or open live panels. I built this because a research agent should be steerable without becoming arbitrary. A directive can change search pressure, but it should not let the system bypass the gates.
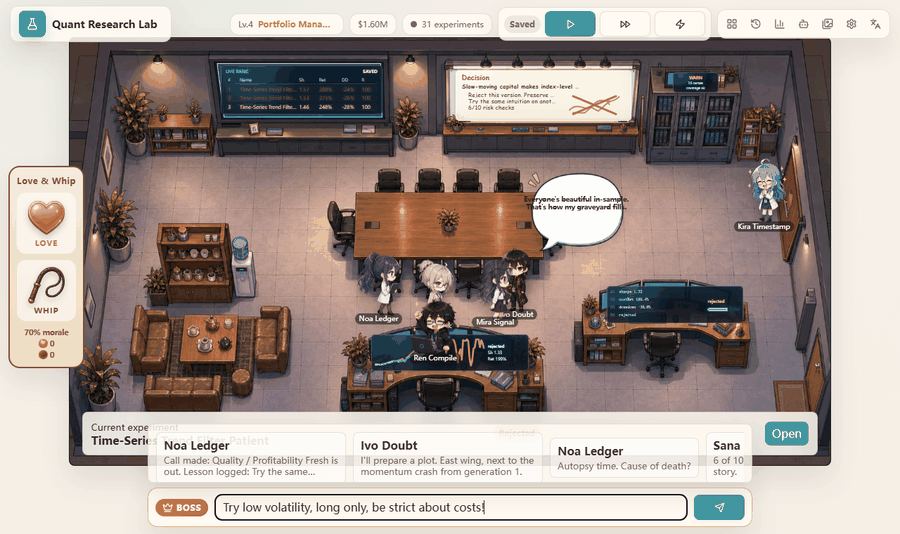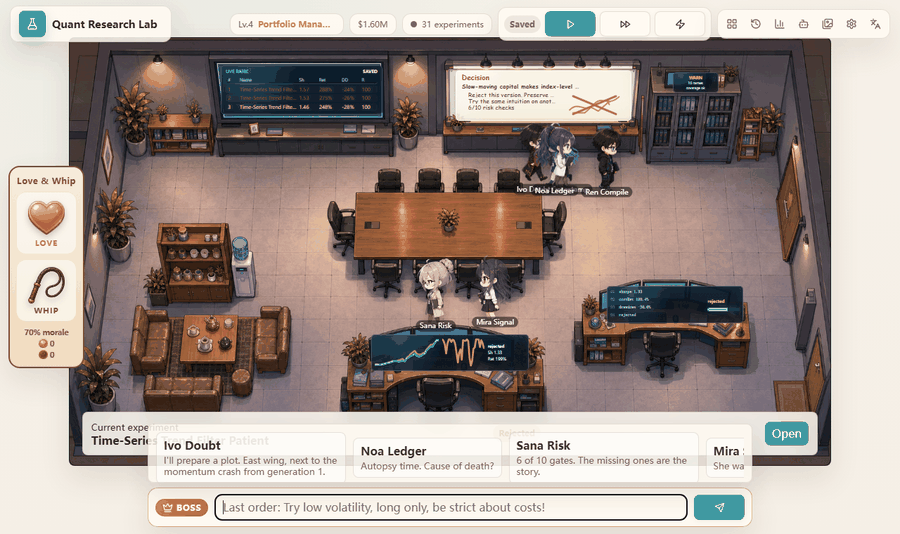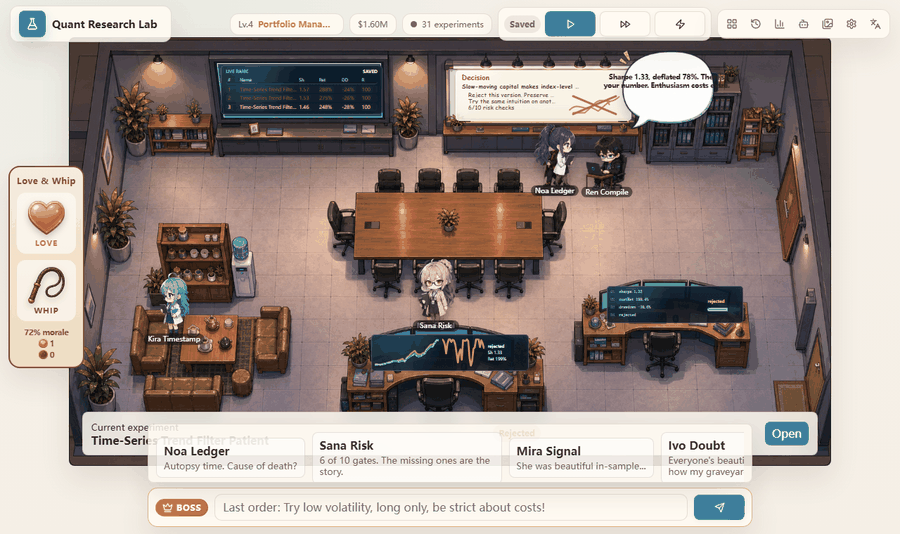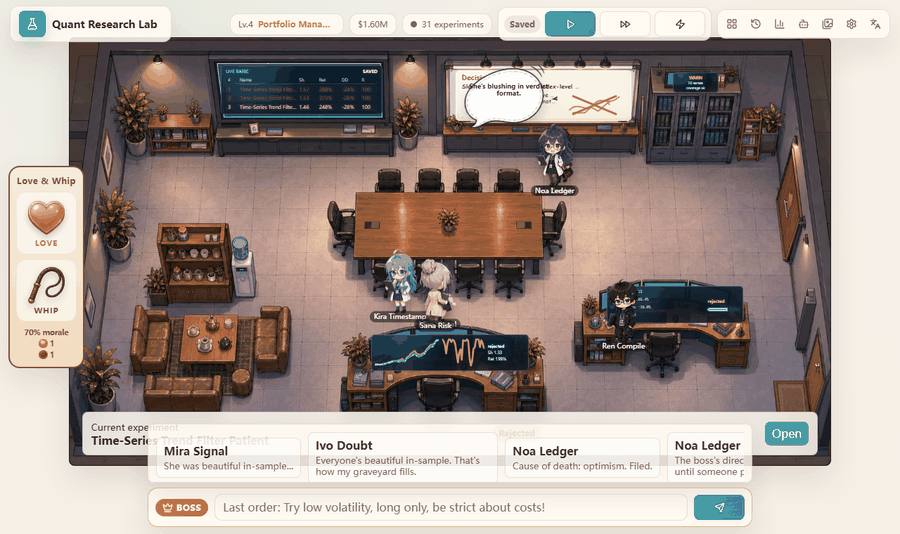
The office demo is useful because it compresses a lot of state into something readable. When the system is generating, auditing, coding, meeting, or reviewing, the page makes that state visible. The user can understand where the loop is instead of staring at a silent notebook cell.
Performance and evaluation
The most important performance target is not raw strategy return. Raw return is too easy to overfit. The project evaluates research quality through the behavior of the loop: whether bad candidates get rejected, whether repeated trials shrink confidence, whether transaction costs matter, and whether new candidates add signal beyond the current pool.
The README reports 6 passing engine tests. They cover determinism, cost monotonicity, deflated-Sharpe shrinkage, directive parsing, and risk gates. That test set is small, but it points in the right direction: the project treats the research engine as software that should be checked, not as a visual toy.
On the quant side, the loop tracks the failure modes that usually make backtests look better than they are:
- Deflated Sharpe penalizes repeated searching across many trials.
- Alpha-pool correlation penalizes candidates that repaint an exposure already in the pool.
- Cost and turnover checks punish strategies that only work in frictionless simulations.
- Drawdown and baseline checks stop the system from promoting fragile curves.
- Research memory records failed branches so the agent does not keep rediscovering the same weak idea.
This means the project is performance-aware without pretending to be a live fund. A good candidate is not just the highest standalone Sharpe. A good candidate is one that survives review, improves the pool, and leaves an auditable lineage.
There is also UI performance. The app is designed as a static Vite build, so it can run locally, in a browser, or as a wallpaper mode. The wallpaper version collapses the boss tools into a floating control orb and pauses when a fullscreen app is in front. That matters because the research office is supposed to be ambient: it can keep running as a visible state machine without demanding a full dashboard all the time.

What I learned
The main lesson is that agent projects need hard boundaries. If an agent can only talk, it can sound impressive while doing very little. If it must call deterministic engines, pass review gates, and update memory, the output becomes easier to audit. The visual layer then becomes useful because it explains the process rather than replacing it.
The next version should make the research allocator more serious. The roadmap I would prioritize is Thompson-sampling direction selection, pool-level delta Sharpe rewards, a MAP-Elites niche archive, probability-of-backtest-overfitting checks through CSCV, and real bridge adapters for Claude Code or Codex. Those changes would make the system less like a demo and more like a controlled autonomous research lab.
Repository: quant-research-lab.